Cut costs and scale smarter by shifting data to Delta Lake.
Introduction
As cloud data volumes grow, so do storage costs. Many organizations continue to store large datasets in expensive systems—such as Cosmos DB, Azure SQL, or managed NoSQL platforms—despite using that data primarily for analytics, not transactional workloads.
This is often a legacy of convenience: applications write to operational stores, and analytics teams read from them—without rethinking where the data should ultimately live.
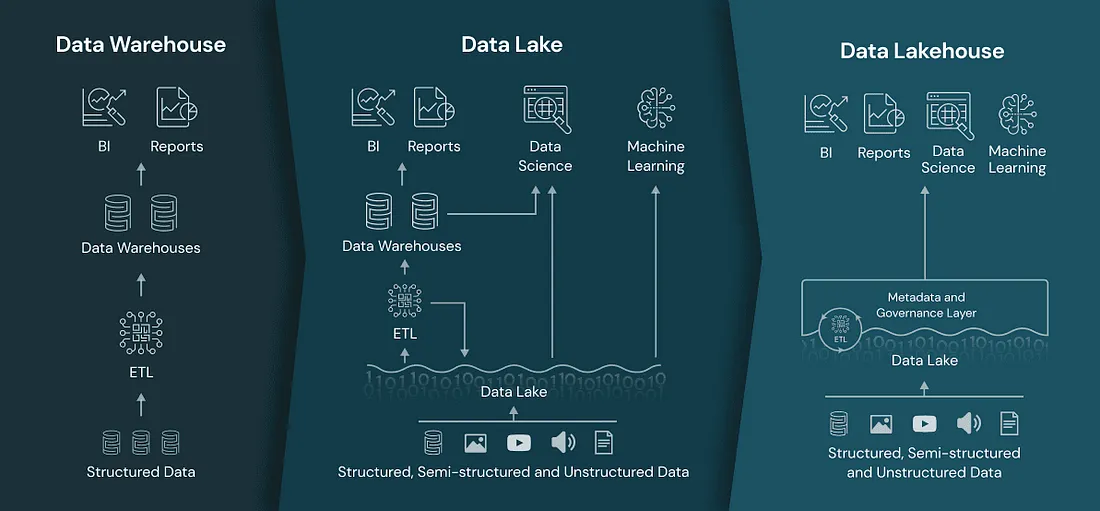
The Storage Optimization Accelerator helps clients rethink their architecture. By shifting cold or infrequently accessed data from high-cost systems into Delta Lake on cloud object storage (e.g., Azure Data Lake Storage or S3), clients can drastically reduce costs while improving performance and flexibility for analytical use cases.
Why This Matters
Cloud-native operational databases are optimized for speed and concurrency—but not for cost-effective analytical scale. When clients store analytical datasets in platforms like Cosmos DB or SQL DB:
- Storage costs balloon for large volumes or long retention periods
- Query costs spike due to high read I/O and throttling
- Historical data is hard to archive or compress efficiently
- Tiered storage strategies become difficult to implement
By contrast, Delta Lake on object storage offers scalable, open-format storage at a fraction of the price—with full support for schema evolution, ACID transactions, and time travel.
This accelerator makes it easy to offload, restructure, and query data cost-effectively—without disrupting operational workflows.
How This Adds Value
This accelerator helps clients:
- Lower total storage costs by migrating high-volume, low-frequency data to cloud-native Delta storage
- Enable downstream analytics with better performance and compatibility via Delta Lake and Databricks SQL
- Simplify data lifecycle management with partitioning, Z-ordering, compaction, and data retention policies
- Maintain access via low-latency queries using Databricks, with optional caching or materialization strategies
- Avoid vendor lock-in through open formats and lakehouse interoperability
Whether for archiving, historical reporting, or active analytics, this accelerator unlocks cheaper, more flexible storage pathways.
Technical Summary
· Source Systems: Azure SQL DB, Cosmos DB, MongoDB, PostgreSQL, etc.
· Target: Delta Lake on ADLS, S3, or GCS
· Migration Patterns:
- Snapshot offloading (full extracts → Delta)
- Incremental sync (via Change Data Capture)
- Hybrid architectures (hot data in SQL, cold in Delta)
· Optimization Techniques:
- Partitioning & Z-ordering
- Data compaction and vacuuming
- File format tuning (e.g., Parquet block size)
· Tooling:
- Delta Live Tables or custom ingestion pipelines
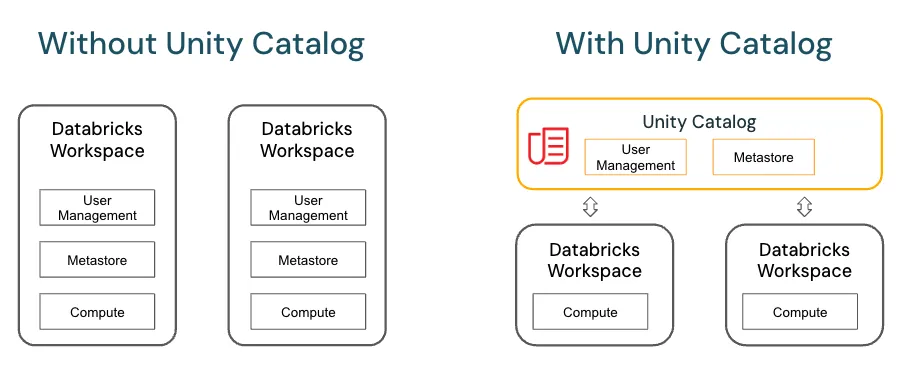
- Unity Catalog for metadata and governance
· Assets:
- Ingestion templates (SQL to Delta)
- Optimization notebooks (e.g., size/compaction)
- Governance and access pattern guide
.svg)









.png)
.png)