The CDC Ingestion Toolkit offers a structured approach for ingesting incremental changes—updates, inserts, and deletes—from relational systems into the lakehouse using scalable, merge-ready logic.
ChangeData Capture (CDC) Ingestion Toolkit Reliable ingestion and merge of change data from transactional systems
Introduction
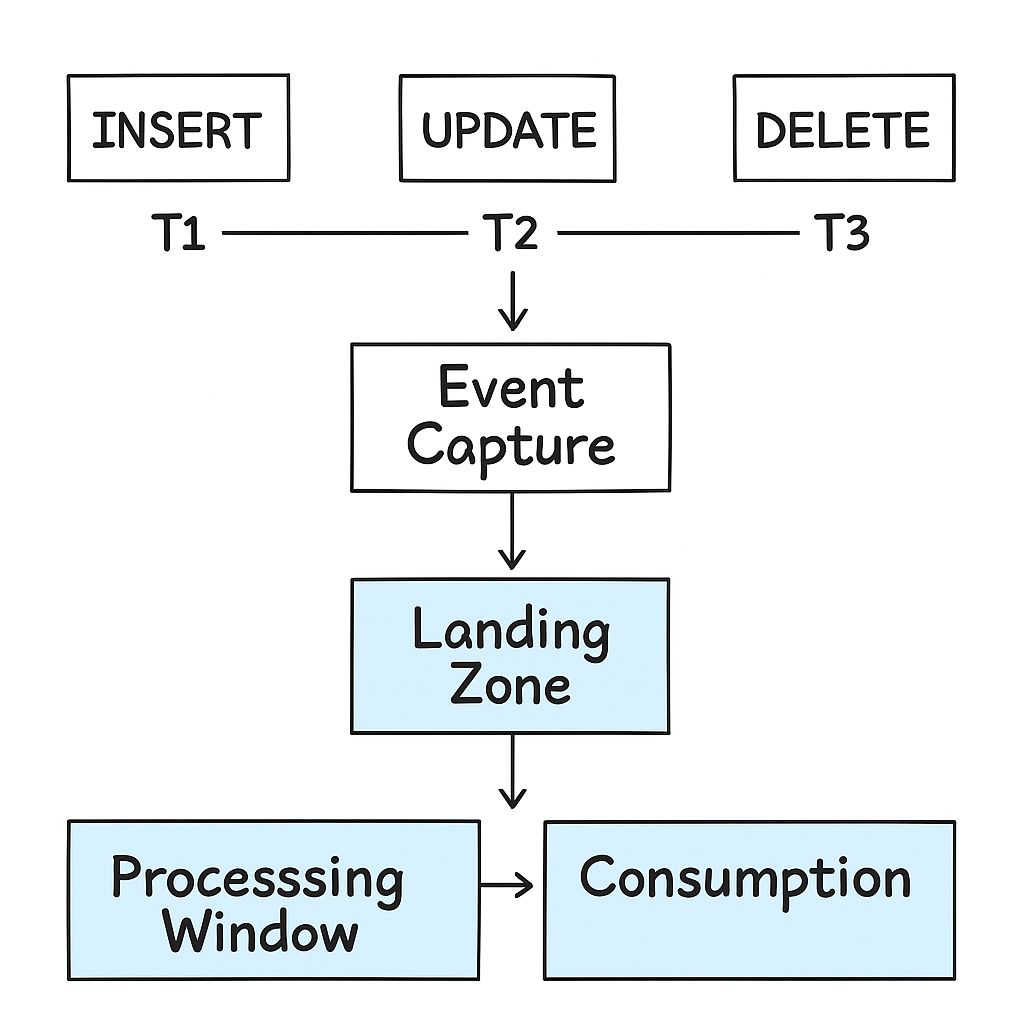
Change Data Capture (CDC) is the foundation of modern data synchronization between operational systems and analytical platforms. Instead of relying on full table reloads or inefficient batch jobs, CDC continuously detects and propagates only the incremental changes—such as inserts, updates, and deletes—that occur in source systems.
The CDC Ingestion Toolkit provides a ready-to-deploy framework for capturing these changes and delivering them into Delta Lake tables on Databricks. It’s designed to be source-agnostic and works with both log-based (e.g., Debezium or Fivetran) and query-based (e.g., timestamp or watermark) extraction patterns. The solution integrates seamlessly with Databricks tools like Structured Streaming, Auto Loader, and Delta Merge to support scalable, replayable, and schema-evolving CDC pipelines.
Clients can use this toolkit to land raw change events in bronze layers, apply smart merge logic to maintain accurate silver tables, and curate fresh datasets for downstream consumption in near-real time.
Why This Matters
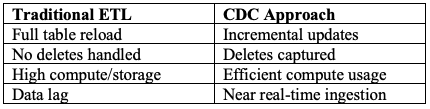
Many data platforms still rely on daily batch loads, even for fast-moving operational data. This creates technical and business debt. Entire tables are reloaded daily, wasting compute and creating pressure on SLAs. Deletes are frequently missed, leading to data duplication or compliance risks. Schema drift can quietly break ingestion logic, and it's often only noticed when downstream pipelines fail.
By contrast, CDC-based ingestion provides precision. Only the changes (inserts, updates, deletes) are applied, and they’re applied fast. This enables data freshness, auditability, and reduced infrastructure overhead. Implementing CDC right, however, requires more than simply wiring up a connector—it needs strong merge logic, replayability, and traceability.
How This Adds Value
TheCDC Ingestion Toolkit provides a production-ready foundation to ingest change logs into Delta tables confidently. Clients benefit from significant operational efficiency, fewer ingestion failures, and better SLAs to the business. Because it's modular and pattern-based, it scales across domains, and simplifies onboarding new data sources.
Reduces data latency while ensuring data correctness.
Scales across multiple source systems with minimal custom code.
Provides a production-grade foundation for near-real-time use cases.
Improves trust in curated data zones and downstream consumption.
.svg)









.png)
.png)