Modernizing how clients land raw data in the lakehouse
Introduction
In every data-driven organization, one of the first steps toward meaningful analytics or AI is getting raw data into the platform reliably, efficiently, and at scale. And yet, this is often where teams stumble.
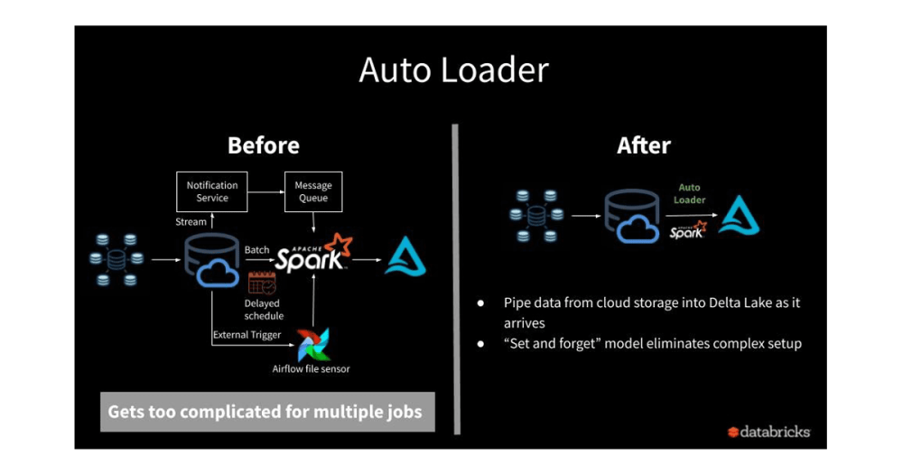
Clients struggle with manually triggered ingestion jobs, pipelines that break when schemas drift, and brittle workflows that require constant developer attention. The cost of this isn't just engineering hours—it’s delayed insights, missed opportunities, and low confidence in the platform’s reliability.
The Auto Loader Ingestion Framework addresses this challenge head-on by providing a prebuilt, production-grade pipeline that continuously ingests files from cloud storage into the lakehouse—using the native capabilities of Databricks Auto Loader. It’s the foundation for any scalable, event-driven, and analytics-ready data architecture.
Why This Matters
When clients begin their data lakehouse journey—or modernize from older platforms—they often underestimate how complex and repetitive file ingestion becomes:
- New files land every hour or day, often in evolving formats.
- Schemas change frequently, especially with semi-structured sources.
- Data engineering teams get pulled into reactive maintenance—fixing failures, handling schema breaks, and retroactively ingesting missed data.
- Business stakeholders wait—sometimes days—for that data to land.
These issues compound quickly in regulated or high-volume environments.Without a resilient ingestion layer, the entire downstream analytics and AI stack suffers.
This framework is about giving clients a confident start—a “no-regret”foundation they can build on.
How This Adds Value
The Auto Loader Ingestion Framework is designed to move fast, scale effortlessly, and require minimal maintenance.
What clients gain:
- Speed to production: Deploy a working pipeline in under a day. No need to reinvent ingestion logic.
- Resilience by design: Handles schema evolution, late-arriving data, and retries with built-in checkpoints.
- Operational simplicity: Low-code, config-driven ingestion that can be adapted across domains or departments.
- Future-proofing: Compatible with Unity Catalog, Delta Live Tables, and structured streaming architectures.
This isn’t just a piece of tech—it’s a strategic enabler. It unblocks the platform. It builds trust in the data. And it frees up engineering time for more valuable work.
Technical Summary
- Source:Cloud object storage (S3, ADLS, GCS)
- Format Support:CSV, JSON, Parquet, Avro, ORC
- Core Tooling:Databricks Auto Loader (
cloudFiles),Delta Lake - Optional Add-ons:Delta Live Tables, Unity Catalog integration, schema evolution logic, checkpointing, metadata tagging
- DeliveryAssets:Python or SQL notebook, parameterized config template, deployable via Databricks Workflows or CI/CD pipelines
.svg)









.png)
.png)