Building and managing ETL pipelines has long been a complex, code-heavy task. From orchestration logic to data quality enforcement, engineers often reinvent the wheel for each new workflow. This results in brittle pipelines, delayed delivery, and rising operational costs.
Build resilient, modular pipelines—without the boilerplate
Introduction
Building and managing ETL pipelines has long been a complex, code-heavy task. From orchestration logic to data quality enforcement, engineers often reinvent the wheel for each new workflow. This results in brittle pipelines, delayed delivery, and rising operational costs.
Lakeflow Declarative Pipelines change that. They let teams define pipelines using simple configurations rather than verbose code—leveraging Delta Live Tables (DLT) and Databricks-native orchestration. With built-in support for dependency resolution, data expectations, lineage, and monitoring, Lakeflow makes pipelines easier to create, scale, and trust.
This accelerator provides clients with ready-to-use templates, design patterns, and operational best practices for adopting Lakeflow quickly and effectively—whether for batch or streaming workloads.
Why This Matters
Traditional ETL development often leads to:
Complex DAGs with hidden dependencies
Low observability—failures go undetected until reports break
Repeated code for schema management, monitoring, or retries
Fragile transitions from development to production
Lakeflow addresses these challenges by abstracting orchestration and infrastructure into a declarative model—letting engineers focus on what should happen, not how to make it happen.
For clients, this means faster pipeline delivery, fewer operational headaches, and more predictable data workflows across domains.
How This Adds Value
This accelerator equips clients with:
Faster time to value: Define pipelines using YAML/SQL configs instead of lengthy Python orchestration logic.
Built-in governance: Track data lineage, expectations, and job history automatically.
.svg)




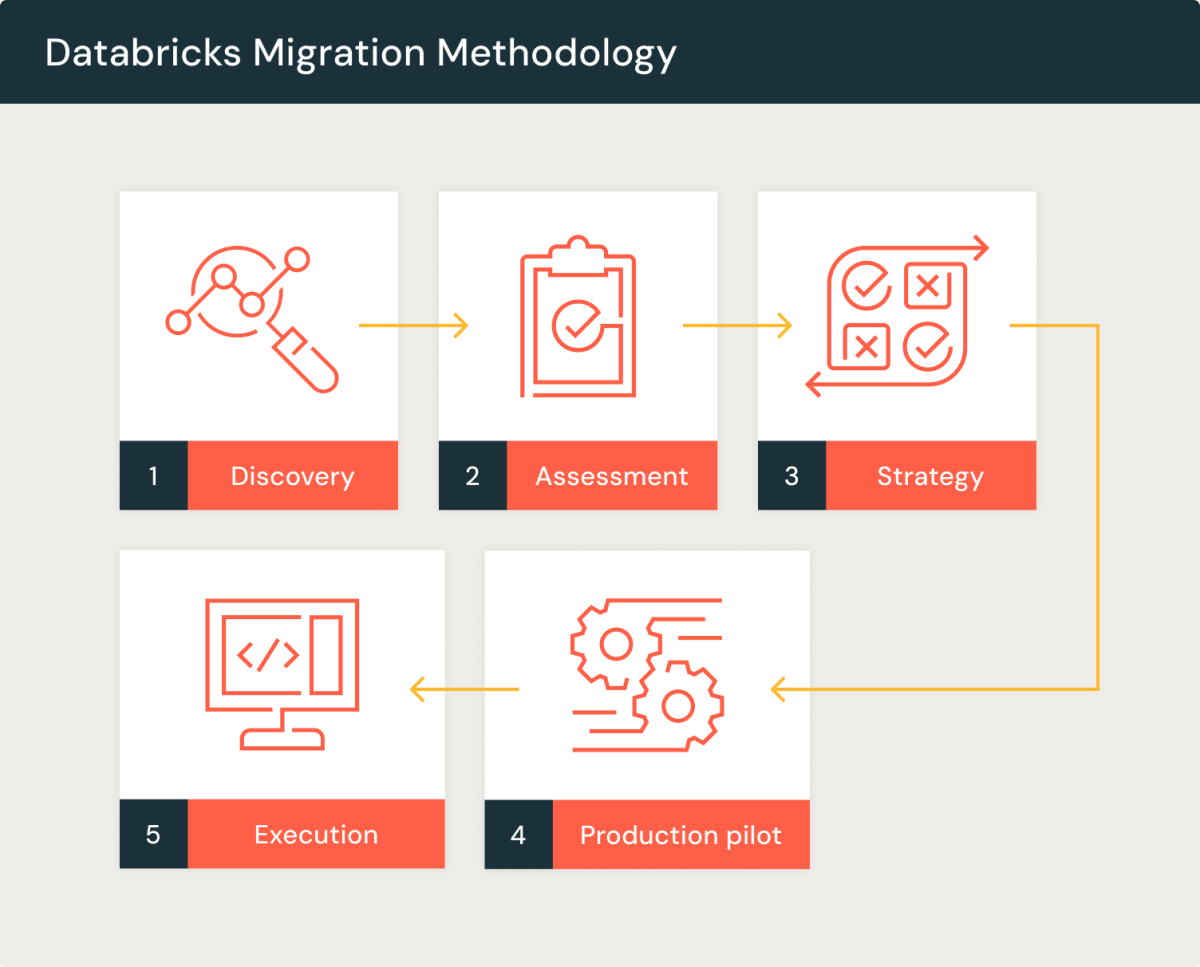



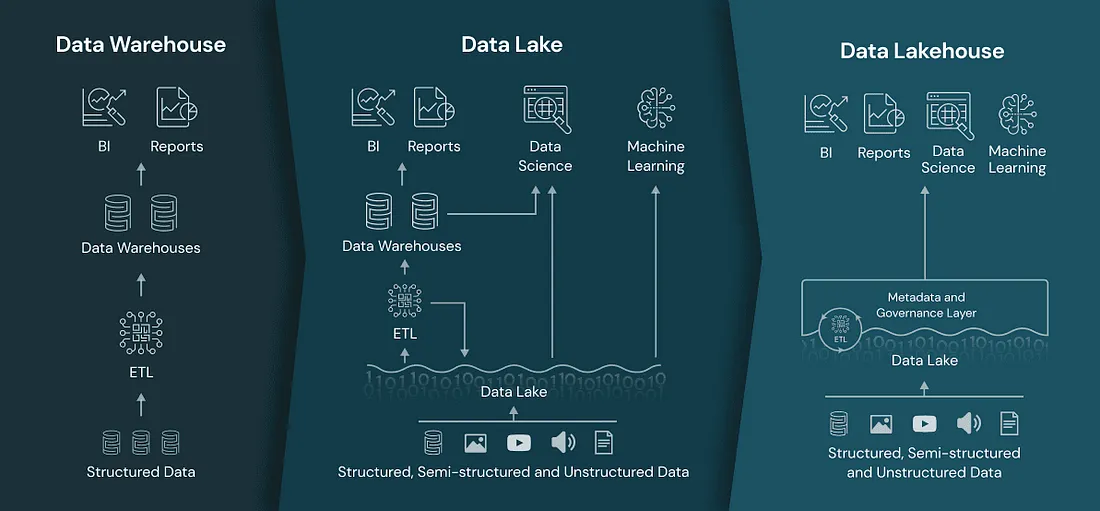

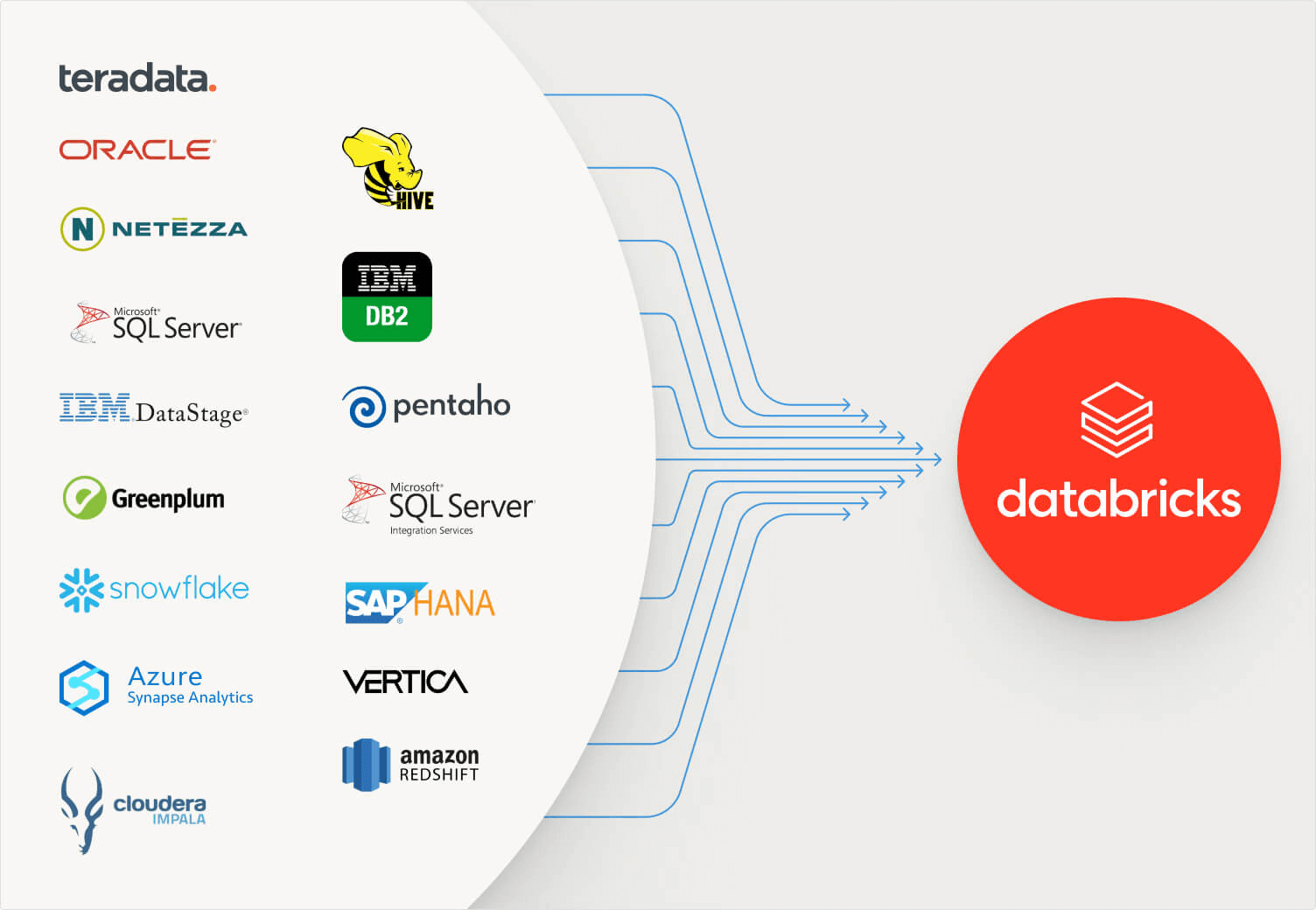



.png)
.png)