Enterprises running on traditional SQL platforms—such as SQL Server, Oracle, Teradata, or Netezza—often find themselves at a crossroads: increasing costs, limited scalability, and a lack of agility for modern analytics and AI. At the same time, moving critical data and logic to a platform like Databricks requires more than just “lift and shift”—it demands careful planning, tooling, and validation.
Accelerating legacy-to-modern SQL workloads with confidence and control
Introduction
Enterprises running on traditional SQL platforms—such as SQL Server, Oracle, Teradata, or Netezza—often find themselves at a crossroads: increasing costs, limited scalability, and a lack of agility for modern analytics and AI. At the same time, moving critical data and logic to a platform like Databricks requires more than just “lift and shift”—it demands careful planning, tooling, and validation.
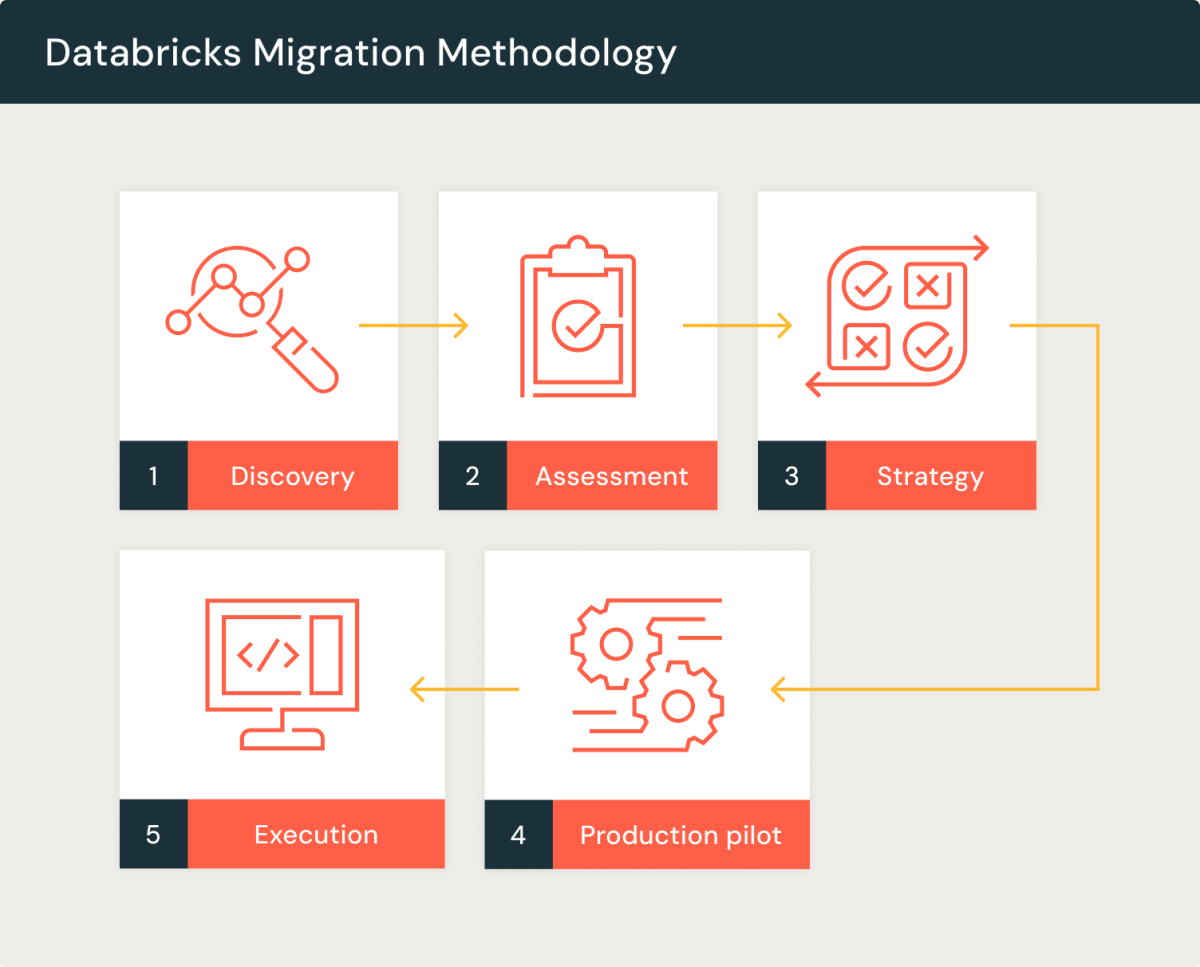
The SQL Migration to Databricks accelerator provides a structured approach for transitioning legacy SQL workloads to the lakehouse architecture. It includes guidance and tooling for syntax conversion, workload decomposition, dependency mapping, and automated testing—minimizing risk while accelerating the path to modernization.
Why This Matters
Legacy data platforms are often expensive, brittle, and hard to scale. Yet organizations delay migration due to fear of operational disruption, lack of in-house skills, and the complexity of rewriting hundreds (or thousands) of SQL scripts.
The risks of not modernizing are just as high:
Costly licenses and inflexible compute models
Siloed data and limited integration with cloud-native tools
Slower time to insight due to outdated batch jobs and monolithic procedures
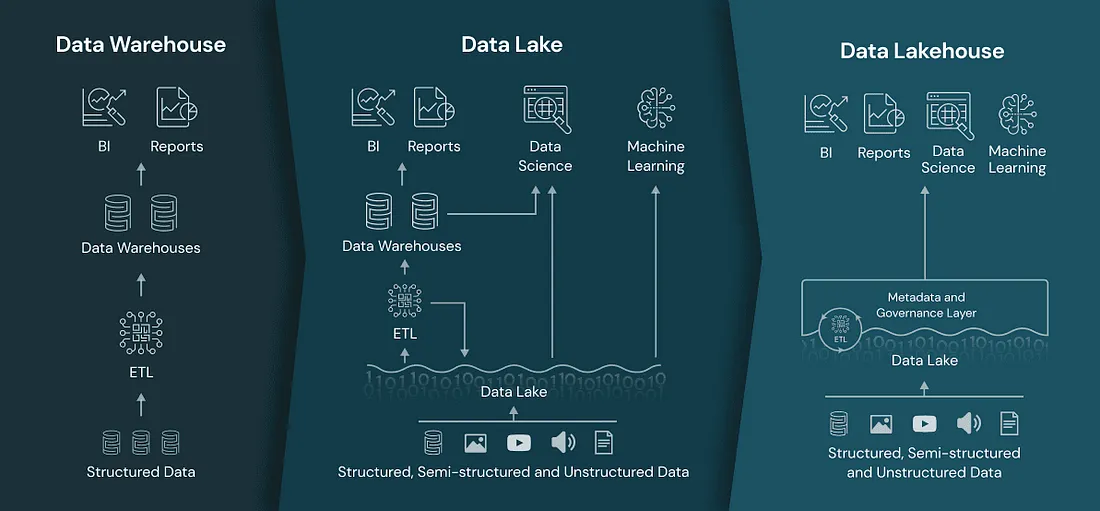
Modernizing to Databricks allows organizations to unify BI, AI, and batch/streaming use cases on a single platform—but only if done with rigor.
This accelerator ensures migrations are predictable, traceable, and value-aligned from day one.
How This Adds Value
This accelerator reduces friction and increases success rates in SQL modernization projects:
Faster migration with templates and automation for SQL dialect conversion (e.g., T-SQL to Spark SQL)
Dependency-aware refactoring through lineage and workload mapping
Risk mitigation with test harnesses, baseline comparisons, and rollback plans
Optimized landing of business logic using Delta Lake, Unity Catalog, and job orchestration patterns
Future readiness by decoupling SQL logic from legacy vendor constraints
It enables teams to confidently sunset legacy systems—while improving performance, governance, and cost-efficiency on Databricks.
Technical Summary
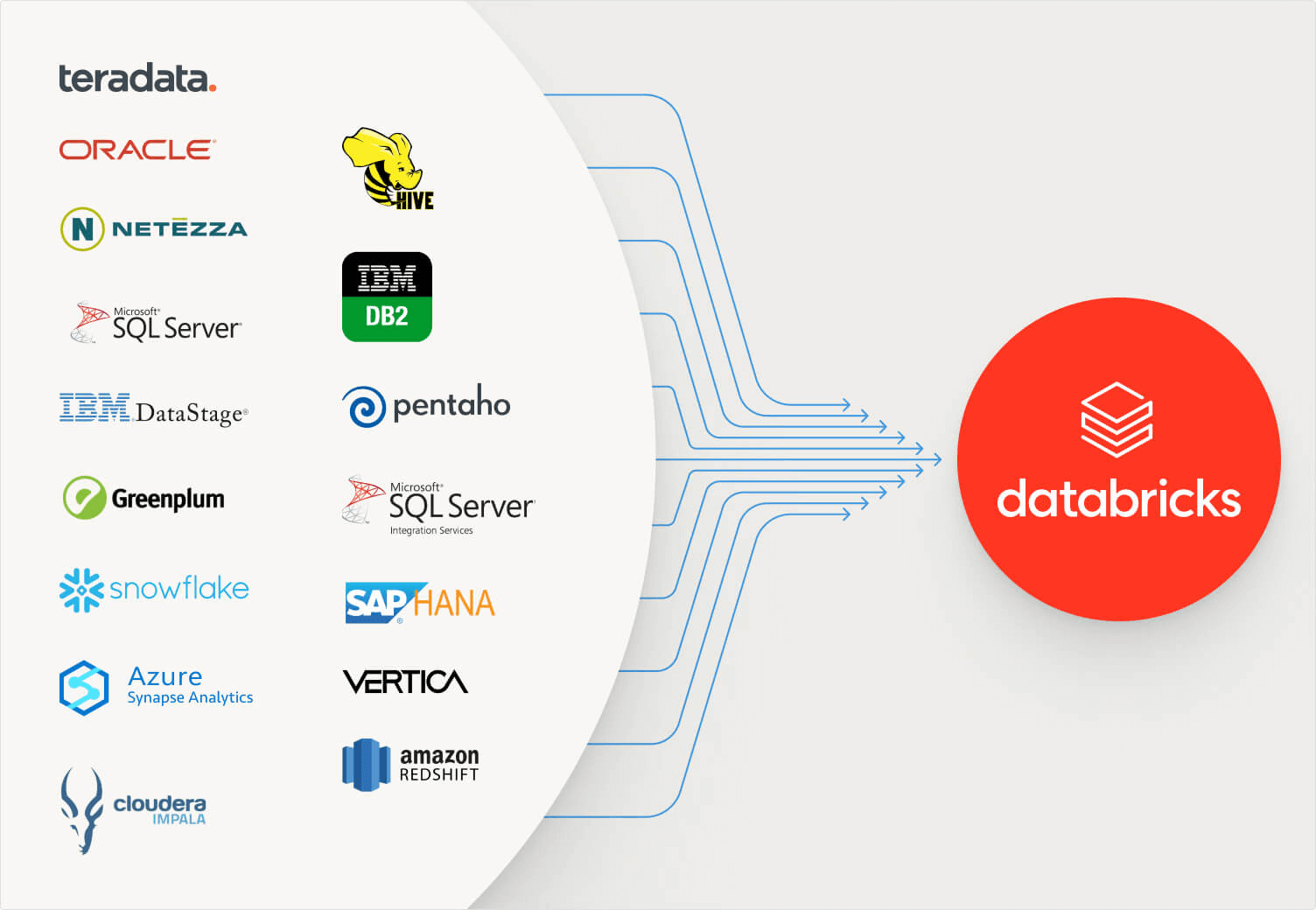
· Source Systems: SQL Server, Oracle, Teradata, Netezza, DB2, etc.
· Target: Databricks SQL, Delta Lake, Unity Catalog
· Migration Components:
SQL parsing & translation (via automated tools or semi-automated mapping)
.svg)









.png)
.png)