The Data Quality Framework brings structure, automation, and accountability to this challenge. Built for Databricks, it integrates directly into ingestion and transformation pipelines, flagging issues early and ensuring only valid trusted data lands in your curated layers.
Proactive validation to ensure trust in the lakehouse
Introduction
High-quality data isn’t a luxury—it’s a prerequisite for analytics, AI, and compliance. And yet, many clients only discover data issues after dashboards break or executives spot anomalies.
The most common causes of poor data quality—null values, schema drift, type mismatches, broken joins—are rarely caught early. Traditional pipelines assume“happy path” inputs and push bad records downstream, where they create far more expensive problems.
The Data Quality Framework brings structure, automation, and accountability to this challenge. Built for Databricks, it integrates directly into ingestion and transformation pipelines, flagging issues early and ensuring only valid trusted data lands in your curated layers.
Whether you're building new pipelines or retrofitting legacy ones, this accelerator puts data quality checks front and center, with minimal overhead.
Why This Matters
Data engineers and analysts alike know the pain of working with broken data:
Dashboards that silently misreport KPIs due to incorrect filters or nulls.
Machine learning models that degrade because of unvalidated features.
Regulatory risks when incomplete or inconsistent data is exposed externally.
Hours spent tracking down the root cause of subtle, pipeline-wide issues.
These problems are usually systemic—not due to bad intent, but due to missing structure around data validation.
The Data Quality Framework helps organizations move from reactive to proactive. It shifts data quality from something teams check manually to something the platform checks automatically, every time new data lands.
How This Adds Value
Clients using this accelerator gain:
Confidence in their data: Issues are caughtearly, not after they reach dashboards or reports.
Reduced operational burden: No need to write one-off validation scripts or reactive fixes.
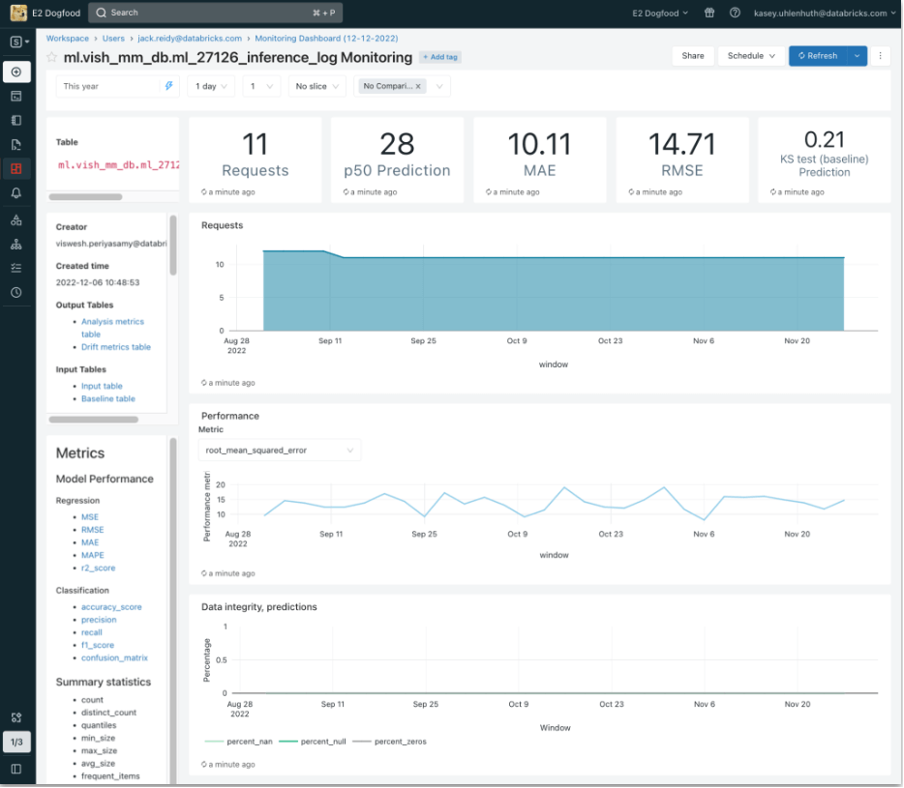
Transparent metrics: Data quality results are logged and surfaced in dashboards, providing visibility to both technical and business users.
Cross-pipeline consistency: Validation rules are reusable and parameterized across domains.
Instead of treating data quality as a downstream concern, this framework embeds it as a core feature of the data platform.
Technical Summary
Validation Types:
Null or empty value checks
Type mismatch detection
Range checks and domain value enforcement
Referential integrity (foreign keys, joins)
Framework Options:
Built-in expectations via Delta Live Tables
Integration with Great Expectations (optional)
Custom Spark logic wrapped in reusable notebooks
Outputs:
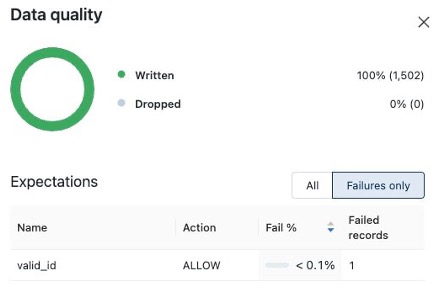
Validation pass/fail logs
Percent-of-passed records metrics
Optional quarantine of bad records
Delivery Assets:
Modular Python or SQL library
Config file to define and manage rules per dataset
Monitoring dashboard template (Databricks SQL or Power BI)
Rick Cobussen
Founder | COO
Published Date:
June 25, 2025
Subscribe to Our News Letter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.svg)









.png)
.png)