Startups and innovative enterprises are revolutionizing the way insurance policies are sold.
Databricks clusters are essential for running scalable and efficient data workloads on the Databricks platform. These clusters consist of driver and worker nodes, which distribute and execute tasks, supporting varied use cases from exploratory data analysis to large-scale data processing. Selecting the right cluster type—Interactive, Job, or Serverless—is key to optimizing performance and cost.
Table of Contents:
Key Cluster Types
Key Concepts to Consider
Choosing the right Cluster Type
Key Cluster Types
Interactive Clusters Designed for real-time, collaborative data exploration and development. Integrated with Databricks notebooks, they are ideal for iterative workflows like model prototyping and exploratory analysis.some text
Use Cases: Data profiling, collaborative development, small datasets (~10 GB).
Best Practices: Enable autoscaling, set auto-termination to control costs, and preload commonly used libraries.
Job Clusters Temporary clusters optimized for scheduled and automated workloads, such as ETL pipelines or batch jobs. Created and terminated automatically, they reduce idle costs and ensure isolation.some text
Use Cases: Regular ETL pipelines, batch processing, model scoring.
Best Practices: Choose appropriate runtimes, monitor job performance, and configure fault tolerance.
Serverless Clusters Fully managed and auto-scaled, serverless clusters are ideal for lightweight, sporadic, or event-driven tasks with minimal setup. They offer high availability and cost-efficiency for smaller workloads.some text
Use Cases: Ad-hoc SQL queries, lightweight ETL, and event-driven jobs.
Best Practices: Enable query caching, monitor costs, and optimize data formats like Delta tables for faster performance.
Key Concepts to Consider
Single-Node vs. Multi-Node Clusters: Single-node clusters are great for small-scale, non-distributed workloads, while multi-node clusters handle larger datasets and distributed tasks.
Cluster Runtimes: Selecting the right runtime (Standard, ML, or Photon) enhances compatibility and workload performance.
Autoscaling: Essential for dynamically adjusting resources to match workload demand and minimize costs.
Choosing the Right Cluster Type
Exploration and Collaboration: Use Interactive Clusters.
Automated and Scheduled Workloads: Opt for Job Clusters.
Lightweight or On-Demand Workloads: Serverless Clusters are best.
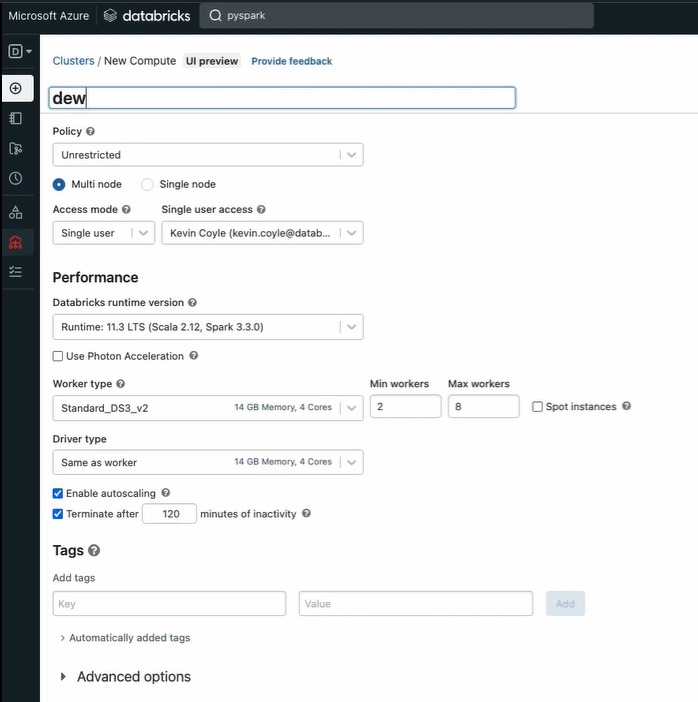
Printscreen of the Databricks cluster creation UI
Databricks clusters provide flexibility and scalability for modern data operations. By understanding their capabilities and selecting the right configurations, organizations can drive efficiency and innovation.
Ferdinand van Butzelaar
Founder | CTO
Published Date:
May 22, 2025
Subscribe to Our News Letter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
.svg)










.png)
.png)